
| 摩登7机器人 |
| CHUANGZE ROBOT |
由企业大模型专家、AI算法工程师、医院信息部门和临床医生组建联合研发团队,在医院场景中直接开发、测试和应用大模型,实施研发应用一体化策略,加速大模型落地应用。基于多模态影像、通用文本、病历文书等语料,构建医疗影像-文本大模型和医疗文本大模型。前者突破传统AI影像的单病种、单器官的研发范式,充分利用大语言模型的文本理解能力,自动挖掘医学影像和诊断报告的相关性,实现大规模数据快速标注,融合语言生成和图像处理两种技术,构建图文混合模态的生成大模型,从医学影像直接生成诊断报告,实现一扫多查。后者通过学习大量专业语料和临床病历,辅助医生书写病历和进行质控,减轻医生工作量,提升书写质量和效率。
当前,医学影像AI已有不少落地场景,但大部分长于计算分析,尚不能直接产生报告,且对每个应用都要训练特定模型,训练时需要人工/半人工标注数据,标注工作耗时费力。因此,能够快速自动标注数据、实现多病同查、直接生成最终报告的影像AI更为符合临床需要。
结构化、内容完整、数据准确、撰写及时的高质量病历是医疗安全和质量的重要保证,涉及医保支付和医院评价。完整病历包括入院记录、首程记录、鉴别诊断、手术计划、执行手术、手术记录、出院记录、术后随访等丰富内容,需要医生记录客观数据并进行大量推理,大大增加了医生负担。病历质控、结构化和辅助信息推断临床需求较大。
本项目主要基于自研的影智医疗大模型,直接采用“研发应用一体化”策略,组建由大模型专家、信息部门、算法工程师和临床专家的混合团队,在复旦大学附属中山医院内开展模型的训练、测试和应用。一是在影像科,开发落地医疗影像-文本大模型产品,突破传统的医疗影像AI模型的研发范式,实现从影像到完整报告的自动生成。二是在临床科室(心外和呼吸内科),开发落地医疗文本大模型产品,实现临床辅助诊断和电子病历辅助结构化书写。
医生根据影像书写报告的过程本质就是对影像进行专业的文本描述,摩登7基于这一点设计“图像-文本大模型”。“图像-文本大模型”具有显著的优势,不仅可以充分利用大语言模型LLM的语言理解能力,自动挖掘文本报告和医学影像内容的相关性,跳过繁琐的精细标注步骤,还可以打破单病种/单器官逐一攻克的研发范式,同时学习到多种器官、病灶的影像特征。
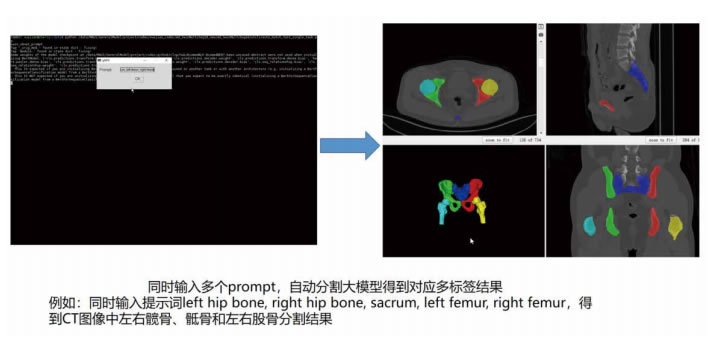
在中山医院影像科的开发工作中,摩登7重点针对冠状动脉CT血管造影 (CCTA)、乳腺钼靶(FFDM)、胸部CT、脑部MR等多模态影像数据进行自动分析,目标是基于病人信息和医学影像快速生成放射影像报告。目前已经实现第一步目标——开发出一种通用的医学图像分割大模型gMIS,该大模型可以只使用少量新样本,就能快速拓展到新的器官或者病灶,如在大模型学习肾动脉血管分割任务时,仅需10个肾动脉训练数据就可以达到传统小模型需要使用200+个数据才能达到的性能水平,显著提升了医疗AI的研发效率。
影智文本大模型是基于100B token的中英文医学语料库训练而成,涵盖医学论文、教科书和诊断指南,确保了模型的专业性和准确性。该模型能根据住院病人的病历记录和医患对话信息,自动生成患者住院期间全流程不同阶段的结构化病历,如首次病程录、手术记录、单病种上报文件及出院小结等。同时,模型还能根据病史辅助生成诊断建议,供医生选择使用。此外,医生可利用本模型轻松完成临床文本数据的导入与管理。该产品在严格标准下的诊断准确率已达80%以上。在推理阶段,模型的处理速度高达50 token/s,USMLE 考试分数为74分(超过ChatGPT3.5得分),表明其专业水平符合医疗执业标准。此外,摩登7整合了RAG(检索增强的生成)技术,使模型在生成文本时能进行动态检索,提高生成内容的准确性和相关性,进一步提升医疗文本处理的效率和质量。
摩登7的模型能够在影像分析中自动完成复杂的数据处理,显著提升工作效率,减轻医务人员负担。此外,通过提供辅助诊断功能,模型能够为医生提供准确的诊断建议,帮助他们更快更精准地作出决策,从而提高医疗服务质量。
目前影智大模型已经在中山医院的几个科室落地使用。未来将通过知识服务收费和个人知识库嵌入为医生提供一个平台,使其能够根据个人需求进行自主创新,同时利用用户反馈进行模型的持续迭代。除了通过入院模式与医院进行合作外,也基于移动APP平台,吸引普通用户和医生用户参与。此外,摩登7也在构建算力生态和语料生态,以支持模型的广泛应用和持续发展。
本项目形成的技术可以平移到其他医院,从而构建一个开放和持续进步的商业模式。
 |
| 智能服务机器人 |
